Deepseek reasoning 対話フォーマット(Reasoning Content)¶
公式ドキュメント
📝 概要¶
Deepseek-reasoner は DeepSeek が提供する推論モデルです。最終的な回答を出力する前に、モデルはまず思考の連鎖(Chain of Thought, CoT)の内容を出力し、最終回答の正確性を向上させます。API は、ユーザーが確認、表示、蒸留に使用できるように、deepseek-reasoner の思考の連鎖の内容を公開しています。
💡 リクエスト例¶
基本的なテキスト対話 ✅¶
curl https://api.deepseek.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $NEWAPI_API_KEY" \
-d '{
"model": "deepseek-reasoner",
"messages": [
{
"role": "user",
"content": "9.11 and 9.8, which is greater?"
}
],
"max_tokens": 4096
}'
応答例:
{
"id": "chatcmpl-123",
"object": "chat.completion",
"created": 1677652288,
"model": "deepseek-reasoner",
"choices": [{
"index": 0,
"message": {
"role": "assistant",
"reasoning_content": "让我一步步思考:\n1. 我们需要比较9.11和9.8的大小\n2. 两个数都是小数,我们可以直接比较\n3. 9.8 = 9.80\n4. 9.11 < 9.80\n5. 所以9.8更大",
"content": "9.8 is greater than 9.11."
},
"finish_reason": "stop"
}],
"usage": {
"prompt_tokens": 10,
"completion_tokens": 15,
"total_tokens": 25
}
}
ストリーミング応答 ✅¶
curl https://api.deepseek.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $NEWAPI_API_KEY" \
-d '{
"model": "deepseek-reasoner",
"messages": [
{
"role": "user",
"content": "9.11 and 9.8, which is greater?"
}
],
"stream": true
}'
ストリーミング応答例:
{"id":"chatcmpl-123","object":"chat.completion.chunk","created":1694268190,"model":"deepseek-reasoner","choices":[{"index":0,"delta":{"role":"assistant","reasoning_content":"让我"},"finish_reason":null}]}
{"id":"chatcmpl-123","object":"chat.completion.chunk","created":1694268190,"model":"deepseek-reasoner","choices":[{"index":0,"delta":{"reasoning_content":"一步步"},"finish_reason":null}]}
{"id":"chatcmpl-123","object":"chat.completion.chunk","created":1694268190,"model":"deepseek-reasoner","choices":[{"index":0,"delta":{"reasoning_content":"思考:"},"finish_reason":null}]}
// ... さらなる思考の連鎖の内容 ...
{"id":"chatcmpl-123","object":"chat.completion.chunk","created":1694268190,"model":"deepseek-reasoner","choices":[{"index":0,"delta":{"content":"9.8"},"finish_reason":null}]}
{"id":"chatcmpl-123","object":"chat.completion.chunk","created":1694268190,"model":"deepseek-reasoner","choices":[{"index":0,"delta":{"content":" is greater"},"finish_reason":null}]}
// ... さらなる最終回答の内容 ...
{"id":"chatcmpl-123","object":"chat.completion.chunk","created":1694268190,"model":"deepseek-reasoner","choices":[{"index":0,"delta":{},"finish_reason":"stop"}]}
📮 リクエスト¶
エンドポイント¶
認証方法¶
リクエストヘッダーに以下の内容を含めて API キー認証を行います:
ここで $NEWAPI_API_KEY はお客様の API キーです。
リクエストボディパラメータ¶
messages¶
- 型:配列
- 必須:はい
これまでの対話メッセージのリストを含めます。注意点として、入力する messages シーケンスに reasoning_content を渡した場合、API は 400 エラーを返します。
model¶
- 型:文字列
- 必須:はい
- 値:deepseek-reasoner
使用するモデル ID。現在、deepseek-reasoner のみがサポートされています。
max_tokens¶
- 型:整数
- 必須:いいえ
- デフォルト値:4096
- 最大値:8192
最終回答の最大長(思考の連鎖の出力は含まない)。思考の連鎖の出力は最大 32K トークンに達する可能性があることに注意してください。
stream¶
- 型:ブール値
- 必須:いいえ
- デフォルト値:false
ストリーミング応答を使用するかどうか。
非対応のパラメータ¶
以下のパラメータは現在サポートされていません:
- temperature
- top_p
- presence_penalty
- frequency_penalty
- logprobs
- top_logprobs
注意: 既存のソフトウェアとの互換性のために、temperature、top_p、presence_penalty、frequency_penalty パラメータを設定してもエラーにはなりませんが、効果もありません。logprobs、top_logprobs を設定するとエラーになります。
サポートされている機能¶
- 対話補完
- 対話プレフィックスの続きの生成 (Beta)
サポートされていない機能¶
- Function Call
- Json Output
- FIM 補完 (Beta)
📥 応答¶
成功応答¶
チャット補完オブジェクトを返します。リクエストがストリーミングされる場合は、チャット補完チャンクオブジェクトのストリーミングシーケンスを返します。
id¶
- 型:文字列
- 説明:応答の一意の識別子
object¶
- 型:文字列
- 説明:オブジェクトタイプ。値は "chat.completion"
created¶
- 型:整数
- 説明:応答作成のタイムスタンプ
model¶
- 型:文字列
- 説明:使用されたモデル名。値は "deepseek-reasoner"
choices¶
- 型:配列
- 説明:生成された応答の選択肢を含む
- 属性:
index: 選択肢のインデックスmessage: ロール、思考の連鎖の内容、および最終回答を含むメッセージオブジェクトrole: ロール。値は "assistant"reasoning_content: 思考の連鎖の内容content: 最終回答の内容
finish_reason: 完了理由
usage¶
- 型:オブジェクト
- 説明:トークン使用量の統計
- 属性:
prompt_tokens: プロンプトで使用されたトークン数completion_tokens: 補完で使用されたトークン数total_tokens: 合計トークン数
📝 コンテキスト結合の説明¶
各対話ラウンドにおいて、モデルは思考の連鎖の内容(reasoning_content)と最終回答(content)を出力します。次の対話ラウンドでは、前ラウンドで出力された思考の連鎖の内容はコンテキストに結合されません。以下の図を参照してください:
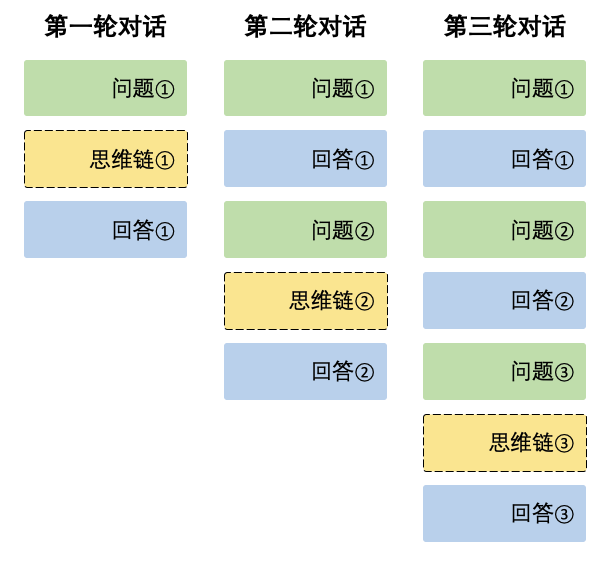
注意
入力する messages シーケンスに reasoning_content を渡した場合、API は 400 エラーを返します。したがって、API リクエストを再度送信する前に、以下の使用例に示す方法で API 応答から reasoning_content フィールドを削除してください。
使用例:
from openai import OpenAI
client = OpenAI(api_key="<DeepSeek API Key>", base_url="https://api.deepseek.com")
# 第一ラウンドの対話
messages = [{"role": "user", "content": "9.11 and 9.8, which is greater?"}]
response = client.chat.completions.create(
model="deepseek-reasoner",
messages=messages
)
reasoning_content = response.choices[0].message.reasoning_content
content = response.choices[0].message.content
# 第二ラウンドの対話 - 最終回答 content のみ結合
messages.append({'role': 'assistant', 'content': content})
messages.append({'role': 'user', 'content': "How many Rs are there in the word 'strawberry'?"})
response = client.chat.completions.create(
model="deepseek-reasoner",
messages=messages
)
ストリーミング応答の使用例:
# 第一ラウンドの対話
messages = [{"role": "user", "content": "9.11 and 9.8, which is greater?"}]
response = client.chat.completions.create(
model="deepseek-reasoner",
messages=messages,
stream=True
)
reasoning_content = ""
content = ""
for chunk in response:
if chunk.choices[0].delta.reasoning_content:
reasoning_content += chunk.choices[0].delta.reasoning_content
else:
content += chunk.choices[0].delta.content
# 第二ラウンドの対話 - 最終回答 content のみ結合
messages.append({"role": "assistant", "content": content})
messages.append({'role': 'user', 'content': "How many Rs are there in the word 'strawberry'?"})
response = client.chat.completions.create(
model="deepseek-reasoner",
messages=messages,
stream=True
)